
The following experiments are using Stable Diffusion Version 1.5 and I’m looking at the Sampling Methods and Sampling Steps to gain a better understanding of how they work for generating new images. I will be using this exact AI Text Prompt for all of the experiments on this page ” Portrait of a cute fox fractal, hyper-realistic, high detail, intricate, high definition, high quality, photo-realistic, 8k, hyper real, photorealistic, detailed –ar 16:9 –version 4 –s 42000 –uplight –no text, blur ” I have personal favorite topic words I use in my text prompt designs that might not make immediate sense but as one works through the many experiments on this blog, my prompt design might make more sense for anyone following the experiments around here.
AIGeneration.blog web interface provides you with access to use Stable Diffusion in your web browser. You can use our web service to run unlimited amount of your own experiments or repeat the following experiments to generate unlimited number of your own AI Generated images.
| Notes | AI Art Generation |
| Sampling Method: Euler a Sampling Steps: 5 Wow, I like the results of this and a little surprised because it has so few steps. |  |
| Sampling Method: Euler a Sampling Steps: 15 This is also alot fewer steps than I generally tend to use with my AI Art Generations, but wow I’m liking the results for this fox concept. |  |
| Sampling Method: Euler a Sampling Steps: 50 Again, I’m really liking the output for my new fox concept. | 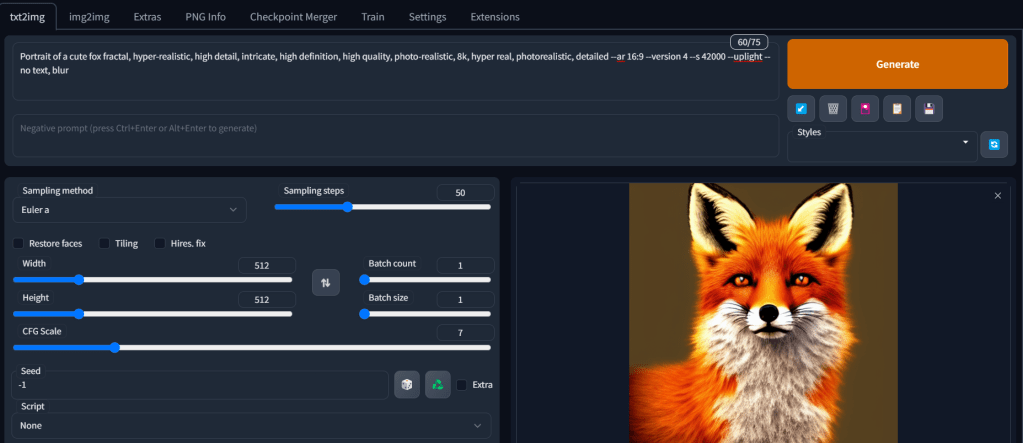  |
| Sampling Method: Euler a Sampling Steps: 100 Ditto, this is nice. I do need to gain more understanding of how to define when I want a full body vs headshot vs portrait. I usually use ‘portrait’ keyword in my ai text prompts for most of my projects at this time. |  |
| Sampling Method: Euler a Sampling Steps: 150 I’m liking the output for a fox. These inspire me to design ai text prompts with action definitions for some of the illustration requirements I have with other projects. |  |
| Next, I will change the Sampling Method while keeping the same max Sampling Steps for the same exact ai text prompt. I will take a much closer look at each of the Sampling Methods later in this article to help us with our future AI Art Generation goals. The current available Sampling Methods with AIGeneration.blog Stable Diffusion Web Interface include: Euler a Euler LMS Heun DPM2 DPM2 a DPM++ 2S a DPM++ 2M DPM++ SDE DPM Fast DPM Adaptive LMS Karras DPM2 Karras DPM2 a Karras DPM++ 2S a Karras DPM++ 2M Karras DPM++ SDE Karras DDIM PLMS | |
| Sampling Method: Euler a Sampling Steps: 150 | |
| Sampling Method: Euler Sampling Steps: 150 Oh my goodness, I love the colors and shape in this result. |  |
| Sampling Method: LMS Sampling Steps: 150 I noticed that watching the image while it’s being generated in the web interface helps me to understand more about hand drawing details for eyes and hair make much more sense when I see the process happening real time with these generations. |  |
| Sampling Method: Heun Sampling Steps: 150 |  |
| Sampling Method: DPM2 Sampling Steps: 150 |  |
| Sampling Method: DPM2 a Sampling Steps: 150 |  |
| Sampling Method: DPM++ 2S a Sampling Steps: 150 |  |
| Sampling Method: DPM++ 2M Sampling Steps: 150 |  |
| Sampling Method: DPM++ SDE Sampling Steps: 150 |  |
| Sampling Method: DPM Fast Sampling Steps: 150 |  |
| Sampling Method: DPM Adaptive Sampling Steps: 150 |  |
| Sampling Method: LMS Karras Sampling Steps: 150 |  |
| Sampling Method: DPM2 Karras Sampling Steps: 150 |  |
| Sampling Method: DPM2 a Karras Sampling Steps: 150 |  |
| Sampling Method: DPM++ 2S a Karras Sampling Steps: 150 |  |
| Sampling Method: DPM++ 2M Karras Sampling Steps: 150 |  |
| Sampling Method: DPM++ SDE Karras Sampling Steps: 150 |  |
| Sampling Method: DDIM Sampling Steps: 150 |  |
| Sampling Method: PLMS Sampling Steps: 150 |  |
After viewing how the Sampling Methods effect the AI Generation, I will take a more in-depth look at each Sampling Method for the rest of this article.
Theories about the Sampling Methods are unproven but many believe that each Sampler Method might have their own strengths in regard to what they generate the best. Some are great for animation, others for faces, others for photo realism and so on. Searching Discord and Reddit Stable Diffusion channels, will show some comparisons but I do prefer experimenting with my own ideas to help me figure out things that are not clearly defined, so here we go.
Sampling Methods, Sampling Step Counts and Batch Output Count choices impact each other and impact the AI Art Generation output. Higher step counts do not guarantee higher quality art and can output garbled art when not used appropriately with the chosen sampler method. Reviewing the quality of your AI Generation Output while verifying the sampler step count & method will enable you to figure out the settings that work best for each aspect of your project. If a higher or max step count is not providing high quality output, it’s an indication that something else in your ai text prompt design needs to be corrected. One way to verify this is to note, copy and paste the same seed and other settings while making variations to your step count setting to be higher and lower to see what happens with the AI Art Generation Output. I like to tweak my ai text prompt designs subject matter, the order I place it, add & remove colors / rendering / lighting words to figure out what works best for my projects. Low step counts can produce high quality AI Art Generation when the ai text prompt is designed to be very specific for your own project requirements.
SAMPLING METHODS
| Euler a (ancestral) is fast. Each generation changes style randomly; more so than plain Euler Sampling Method. Provides fast & good output with low step counts of 8 to 16. It changes style dramatically more than the DDIM sampler method, so you might not find this one as useful as DDIM because DDIM is usually preferred for fast iterations while brainstorming prompt ideas. Euler a can produce excellent results with smaller steps (5 – 10) so this is a worthy fast high quality sampling method for some projects. When you get an output you like with Euler a , you can try tweaking it more with DDIM to get the best benefits of each sampling method while brainstorming your own ai text prompts. Euler a Theories: fast results with less steps. Probably good for anime, cartoon, landscape, environment and architecture visuals. Probably Not good for photo real visuals. Soft. Artsy. Softer Hair. |
| Euler is a single step method that refers to only one previous point and its derivative to determine the current value. Euler Theories: fast results with less steps. Probably good for cartoons with less details and more stylistic visuals. Probably good for architecture, prototyping fashion, jewelry, accessories, character sheets, stylized, punk, highly stylized visuals. Probably Not good for sfumato, blending, chiaroscuro and similar techniques. Soft. Artsy. Blends colors the most. Photoreal soft visuals. |
| LMS (Linear Multistep Methods) are used for numerical solution of ordinary differential equations. Multistep methods try to gain efficiency by keeping and using info from previous steps instead of discarding them; referring to several previous points and derivative values LMS Theories: nice eye details. Probably good for cartoon, painterly landscapes, architecture, environment. Probably not good for real world details, photo real visuals, characters, hands, feet. Soft. Artsy. |
| Heun Theories: fast results with less steps. Ideal for Landscape Generations, sketch styles, painterly styles. Probably good for underwater, glass and creature generations. Soft and Artsy Visuals. |
| DPM2 is slow if used to fix DDIM issues – best to design with DDIM first, then bring your favorite AI Text Prompt design to DPM2 when you want more anime and cartoon style generations. Diffusion Probalistic Models (DPM) are generative models that solve corresponding diffusion ordinary differential equations (ODEs) and they can be slow. Soft and Artsy visuals. Sharper Hair. DPM2 Theories: Probably good for anime, cartoon, sfumato, chiaroscuro, gouache, and 90s styles and techniques. Probably good for photo real. |
| DPM2 a indicates this is a Second Order Ancestral sampling method. This is very slow compared to the other sampling methods and works really well in the 30 – 80 sampler step range. This is a great option with your high quality ai text prompts and not a good option for fast iterative experiments, because it is so slow. It’s probably best to use this sampling method with the ai text prompts you already know, love and feel it’s worth it to wait much longer to get the final ai generation output. If you do not have personal favorite ai text prompts yet, use the super fast DDIM and Euler a sampling methods to figure out what your personal favorites are before using this slower but high quality output sampling method. DPM2 a Theory: Probably good for anime, cartoon, sfumato, chiaroscuro, gouache styles and techniques. Probably not good for photo real visuals. Soft. Artsy. |
| DPM++ 2S a DPM++ is an indicator this sampling method is an improved sampler of DDIM. 2S a indicates this is a Second Order Single Step Ancestral sampling method. DPM++ 2S a Theories: Probably good for artistic balanced colors with less exaggerated lines. Probably good for ‘dream’ like styles. Probably not good for photo real visuals and details. Soft. Artsy. |
| DPM++ 2M DPM++ is an indicator this sampling method is an improved sampler of DDIM. 2M a indicates this is a Second Order Multistep sampling method. DPM++ 2M Theories: Seems to make decent human hands, flowy hair and flowy lines. Probably good for nice lighting, shadows, colors, shapes and old fashion cartoon styles. Probably not good for photo real and detailed styles and techniques. Soft. Artsy. |
| DPM++ SDE DPM++ is an indicator this sampling method is an improved sampler of DDIM. SDE a indicates Theories: Makes nice eye, ear, face details, colors, lighting, shadows with late 1970s to 1980s vibe. Probably good for cartoons. Probably not good for photo real and detailed visuals. Soft. Artsy. |
| DPM Fast Theories: Very nice old fashion cartoon and painterly style with nice eye details. Probably good for punk styles, contemporary, chiaroscuro, gouache and similar techniques & styles. Probably not good for photo real results. Provides most variety & flexibility with faces. Simple backgrounds that bring out the main subject. Soft. Artsy. |
| DPM Adaptive Theories: nice background and glow effect to put focus on main character in center. Nice for old fashion cartoon styles, painterly styles. Probably not good for photo real details. Soft. Artsy. Clearest Sharpest Eyes |
| LMS Karras LMS indicates Karras indicates this sampler is using a specific type of noise. Theories: Makes nice eyes. Nice flowy lines. Probably nice for abstract concepts that don’t require face and body details, perhaps underwater and outerspace scenes. Not good for detailed appendages, hands, ears, face, photo real visuals and styles. Soft. Artsy. |
| DPM2 Karras DPM2 indicates this is a Second Order sampling method. Karras indicates this sampler is using a specific type of noise. Theories: Good with painterly, sfumato-esque details, lighting, shadows. Probably not an option for photo real visuals and styles. Soft. Artsy. |
| DPM2 a Karras DPM2 a indicates this is a Second Order Ancestral sampling method. Karras indicates this sampler is using a specific type of noise. DPM2 Theories: good for anime / cartoon visuals. mouths are more narrow on characters. Soft. Artsy. a Karras Theories: Good with detail placements, lighting, shadows, cartoon, painterly styles. Might not be good for photo real visuals and styles. |
| 2S a Karras DPM++ is an indicator this sampling method is an improved sampler of DDIM. 2S a indicates this is a Second Order Ancestral sampling method. Karras indicates this sampler is using a specific type of noise. Theories: wider mouths and head size on characters. Sketch blurred visuals. |
| DPM++ 2M Karras DPM++ is an indicator this sampling method is an improved sampler of DDIM. 2M a indicates this is a Second Order Multistep sampling method. Karras indicates this sampler is using a specific type of noise. Theories: ideal for generating cute faces. more sketch visual when compared with DPM 2 a. Hair features are not as flowy when compared to Ancestral Karras and Second Order Ancestral Karras (DPM2 a / DPM++2S a). Soft. Artsy. |
| DPM++ SDE Karras DPM++ is an indicator this sampling method is an improved sampler of DDIM. SDE indicates this is Karras indicates this sampler is using a specific type of noise. Theories: cute short wider faces, wider set eyes, wider set ears. nice flowy hair and fur details. Soft. Artsy. |
| DDIM DDIM provides fast great results. It’s a first choice when I need to generate many images very quickly; brain storming & testing new prompt designs to tweak further. DDIM with lower Sampling Steps (8 to 14) with a batch output of 4 to 9 images is a good way to quickly see how a prompt idea will do across multiple seeds. If the output is not good enough, you can tweak the Sampling Steps to use higher numbers to 15, 25 and 35 to see if your ai text prompt idea is going to work for your project or not. If higher Sampling Steps still do not provide good output, it’s time to tweak other aspects of your prompt with the original low Sampling Steps until your prompt ideas output something you are happy with. Then try again with higher number of steps and with some of the other Sampling Methods available. Many AI Text Prompt Designers prefer to use both Euler and DDIM to figure out new AI Text Prompt Designs because DDIM is fast & consistent while Euler is a little slower, with random drastic changes between step numbers but also provides high quality generations. Theories: Fast Results with Less Steps. Great for brainstorming new prompt designs quickly. Nice eyes and face details, shapes, sizes. Nice lighting, shadows. My favorite ‘fast prototyping’ Sampling Method. Soft. Artsy. Big Soft Blur. Softest, Smoothest Eyes. |
| PLMS Theories: Nice expressive eyes, face, fur details. Probably nice for architecture, fashion, knolling and papercutting output. Soft. Artsy. |
I’m stopping my experiments here for now and hope this article will serve as a decent reference for future experiments. Let me know what you think about all of this: tag me in your social media posts about AI Art Generation ( @monigarr ). If you appreciate what we are doing with this website: sign up to access our private Stable Diffusion web interface to make unlimited numbers of your own AI Art Generations.
REFERENCES:
Abraham, T. M. (2022, August 31). Sampler vs Steps. Retrieved February 5, 2023, from https://twitter.com/iScienceLuvr/status/1564847717066559488
Dahlquist, Germund (1963), A special stability problem for linear multistep methods. Retrieved February 5, 2023 from BIT, 3: 27–43, doi:10.1007/BF01963532, ISSN 0006-3835, S2CID 120241743.
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., & Zhu, J. (2022, October 13). DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps. Arxiv.org. Retrieved February 5, 2023, from https://arxiv.org/abs/2206.00927
Mlynarczyk, A. (2022, December 7). Stable Diffusion and the Samplers Mystery. Weights and Biases. Retrieved February 5, 2023, from https://wandb.ai/agatamlyn/basic-intro/reports/Stable-Diffusion-and-the-Samplers-Mystery–VmlldzoyNTc4MDky
P. (2022, October 1). How to get images that don’t suck: A Beginner/Intermediate Guide to Getting Cool Images from Stable Diffusion. Retrieved February 5, 2023, from https://www.reddit.com/r/StableDiffusion/comments/x41n87/how_to_get_images_that_dont_suck_a/
Rombach, Robin and Blattmann, Andreas and Lorenz, Domink and Esser, Patrick and Ommer, Bj. (2022, June). Stable Diffusion Version 1.5. Retrieved February 5, 2023 from https://huggingface.co/runwayml/stable-diffusion-v1-5
Karras, T., Aittala, M., Aila, T., & Laine, S. (2022, June 1). Elucidating the Design Space of Diffusion-Based Generative Models. Arxiv.org. Retrieved February 5, 2023, from https://arxiv.org/abs/2206.00364

5 responses to “Stable Diffusion Sampling Methods”
[…] with DPM Fast Sampling Method when I’m fine tuning my AI Text Prompts at this previous blog post: https://aigeneration.blog/2023/02/06/stable-diffusion-sampling-methods/ […]
[…] our previous article “Stable Diffusion Sampling Methods” for details about the features and behavior for each sampling methods, including why I start […]
[…] our previous article “Stable Diffusion Sampling Methods” for details about the features and behavior for each sampling […]
[…] Referring to my previous experiments where I looked at the various Stable Diffusion Sampling Method options, I decided to use the following sampling methods for this set of experiments because they are probably best suited for generating environment visuals and paper arts. Sampling Method Details […]
[…] results I want to AI Generate. See my previous article for details: AI Prompt Design: Euler A and AI Prompt Design: Sampling Methods for more […]